Whitepapers
The Strategic Relevance of Retrieval Augmented Generation
The mass adoption of Large Language Models “LLMs” has helped shift the technology paradigm and ushered in a new medium to work with information. Despite recent advancements, these technologies are still relatively new and have their limitations, especially when it comes to developing domain-specific capabilities. Across several Generative AI projects, we’ve heard business leaders consistently emphasize two non-negotiable requirements. Firstly is the need to prioritize user trust and ensure answers are grounded in relevant, verifiable information. Secondly is the need to develop capabilities that leverage the institutional domain knowledge of the organization. These two requirements address a fundamental concern surrounding LLMs eloquently articulated by Pinecone Manager James Briggs.
He underscores that these models are frozen in time as “they only know the world as it appeared through their training data.” This training data is not always up-to-date and primarily relies on general information, which makes the models less effective when asked to provide domain-intensive answers. This creates scenarios where models can ‘hallucinate’ and produce highly convincing, yet ungrounded answers. The purpose of this article is to explore how enterprises can develop Generative Chat capabilities that are (a) trustworthy, and (b) can operationalize the organization’s unique intellectual capital.
Potential Solutions
Prompt Engineering
There are a few methods to tackle the inherent challenges faced by LLMs. The first approach is prompt engineering, which involves the user supplying the model with contextual data within their prompt, thereby equipping the LLM with the necessary information to formulate a response. Let’s look at an example:
Prompt: Considering the research paper “Attention Is All You Need”, can you explain the concept of Self-Attention and provide a practical example?
Here, the user includes the complete text of the “Attention Is All You Need” paper within the prompt.
In this scenario, the LLM draws upon the domain knowledge embedded within the prompt—in this instance, the entire text from the research paper “Attention Is All You Need,” and generates a response based on this specific knowledge base. However, there are limitations to prompt engineering. One significant drawback is that it places the burden on the user to supply the pertinent information, which is not conducive to a seamless experience. Additionally, character constraints often restrict the volume of data that can be embedded in a prompt, which is problematic for organizations wishing to integrate extensive bodies of information, such as large collections of papers or internal documents.
Fine-Tuning
Moving beyond prompt engineering, another widely adopted approach is fine-tuning pre-built models from providers like Azure OpenAI, Google, or Meta. Fine-tuning involves adapting a pre-existing model by training it on organization-specific data, thereby tailoring its responses to be more aligned with the organization’s domain knowledge. However, this method also has its drawbacks. Not only is it resource-intensive, time-consuming, and costly, but it also requires periodic retraining as the information evolves to ensure the data is up to date, bringing us back to the original data freshness challenge.
Retrieval Augmented Generation
The best solution we have encountered is Retrieval-Augmented Generation, commonly abbreviated as “RAG.” RAG represents an innovative approach in Natural Language Processing “NLP” that integrates the capabilities of retrieval-based models with generative language models. This combination empowers RAG to process an input question, search through an external knowledge repository for relevant data, and generate a response based on this information that is coherent and grounded. What sets RAG apart is its ability to enable LLMs to tap into information beyond the confines of their training data. Think of this external knowledge repository as an adaptable long-term memory for the LLM. This knowledge base is not set in stone and can be continuously updated and refined. Enterprises can add new data and remove outdated information on the fly without having to go through the expensive process of retraining foundational models. In a recent interview with the Financial Times’ George Hammond, Cohere Co-founder & CEO Aidan Gomez emphasizes the strategic relevance of RAG in building trust in responses generated by LLMs. Gomez discusses the capabilities of Retrieval Augmentation, stating, “What you can do there is force the model to actually cite its sources. Now, you have the ability to verify these models.” The ability to cite sources and present verifiable information represents a significant stride in mitigating instances of hallucinations and building user trust. This is especially important in highly regulated sectors like healthcare or finance, where the consequences of misinformation can be particularly grave.
Putting RAG into practice
From a practical standpoint, Figure 1 presents a high-level architecture that we have used to deploy RAG when developing Generative Chat applications. Before walking through the specifics of Figure 1 we will first define a few key terms and concepts that are critical to understand:
- Embeddings: In NLP, embeddings are a way to represent words through vectors composed of real numbers. These vectors are essential because they capture the semantic meaning of the words. The vectors are arranged in a space where words of similar meanings are closer to each other. Services like OpenAI’s Ada or Cohere’s Co.Embed offer embedding models that can encode text into these numerical representations, enabling us to map the user’s question to the right domain knowledge. Think of embeddings as the neural connections in your brain that form whenever you learn a new word or concept. When you are studying for an exam, your brain is creating and strengthening these neural connections as you understand and internalize various pieces of information that you are consuming.
- Vector Databases: Building on the concept of embeddings, a vector database is a specialized storage system that holds data in the form of high-dimensional vectors. These vectors are essentially lists of numbers that represent various features or attributes, much like the numerical representations of words in embeddings (a type of vector). The number of dimensions in each vector can vary from a few to thousands, reflecting the complexity and richness of the data being represented. Vector databases are optimized to handle these kinds of data efficiently, and are crucial in applications like Generative Chat where one needs to rapidly search through and retrieve information based on semantic similarity. Imagine your brain’s long-term memory as a vector database. When you study, your brain is not just creating neural connections (embeddings), but it’s also organizing them efficiently in your long-term memory (vector database) where the information is stored and can be retrieved based on the exam’s questions.
- Vector Similarity Search: Continuing from the notion of vector databases, vector similarity search is the process of identifying vectors that are most similar to a given query within the knowledge base. The key aspect here is the measurement of similarity, which can be defined through different mathematical metrics like cosine similarity or Euclidean distance. In the context of NLP, vector similarity search is critical as it allows us to find semantically related content to a given input. Continuing with the studying analogy, your brain performs a vector similarity search when you answer a question on the exam. It quickly scans through your long-term memory (vector database) to find and retrieve the most relevant neural connections (embeddings) related to the question. In the case of Generative Chat applications, this mechanism helps with efficiently retrieving the most relevant information from a vast database to generate responses that are coherent and contextually aligned with the user’s query. Cloud Vector Databases like Pinecone, Azure Cognitive Search, and Google Cloud’s Vertex Matching Engine are optimized for performing vector similarity searches at a massive scale.
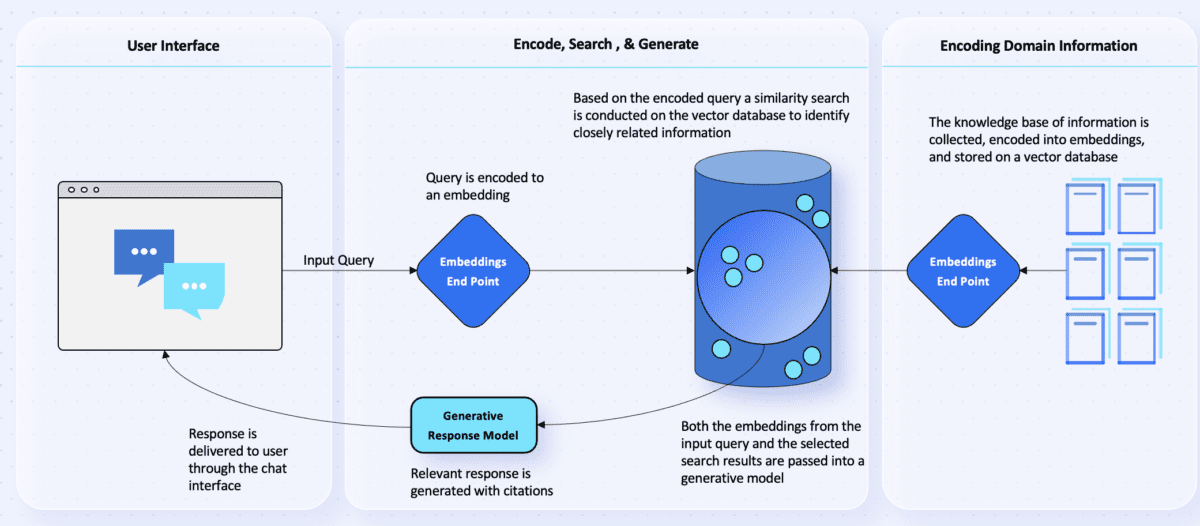
Figure 1. High Level RAG Process Flow
To better illustrate the steps in Figure 1, let’s consider a hypothetical scenario where a Pharmaceutical Company is developing a generative medical research agent to empower their R&D team to ask questions and efficiently retrieve information. This is a particularly good application of RAG because so much medical data is unstructured, making it difficult to navigate efficiently, and the stakes are high for accurate results. We’ll begin by explaining the steps on the right-hand side of Figure 1, which focus on Encoding the Domain Information.
- Gather Domain Information: The Development team begins by accumulating a wealth of domain knowledge, including medical journals, lab studies, credited articles, patents, research papers, drug formulas and compounds, and other sources that are deemed reliable and relevant.
- Encoding the Knowledge Base:This collected knowledge base is then processed through an Embeddings End Point, which converts the information into numerical vectors or embeddings.
- Storing in Vector Database: The generated embeddings are then stored in a Vector Database, ready for efficient retrieval based on semantic similarity.
Now, let’s say the system has been launched, and the researchers have begun using the internal R&D agent to ask questions. We’ll now walk through the steps on the left-hand side of Figure 1.
- User Query: At the User Interface Layer, a researcher poses a question to the agent, such as: Is there any clinical evidence to suggest mycophenolate mofetil could be used for other conditions beyond being a immunosuppressant for Organ Transplants?
- Encoding User Query: This question is converted into a vector representation (embedding) through the Embeddings End Point.
- Vector Similarity Search:The Vector Database conducts a real-time similarity search, comparing the query’s vector to those in the database.
- Selecting Top Candidates: The search identifies the best matches for a response based on the encoded user’s query.
- Generating Response: The vector representations of both the original input query and the selected search results are passed into a Generative Response Model, like GPT-4.
- Providing Answer with Citation: The model generates an answer along with a citation for verification. For instance: Yes, Mycophenolate Mofetil (CellCept) is an immunosuppressive agent that has been used in the treatment of autoimmune conditions like lupus because of its ability to target T- and B- lymphocytes leading to the suppression of the cell mediated immune response and antibody formation. Please see the following Nature Journal which outlines how Mycophenolate Mofetil can be an effective treatment option. (Source Provided)
Measuring Value
As organizations navigate the choppy economic waters of the past two years, it’s critical to anchor any AI endeavour, including the technical approach, to a solid business case. This case should clearly define both short and long-term value drivers to ensure stakeholders can highlight quick wins along their journey. This is especially important given the heightened buzz surrounding Generative AI, largely spurred by consumer applications. This has generated a flurry of use cases and, in tandem, a rise in skepticism. The degree of skepticism has only been fuelled by recent mistakes such as a New York lawyer submitting a brief citing fictitious casesgenerated by ChatGPT hallucinations, a far cry from the tool’s intended use.
Based on the hypothetical use case of building a research agent for a Pharmaceutical company, we will outline the potential value of both the application and our architectural approach in leveraging RAG in the value framework outlined in Figure 2.
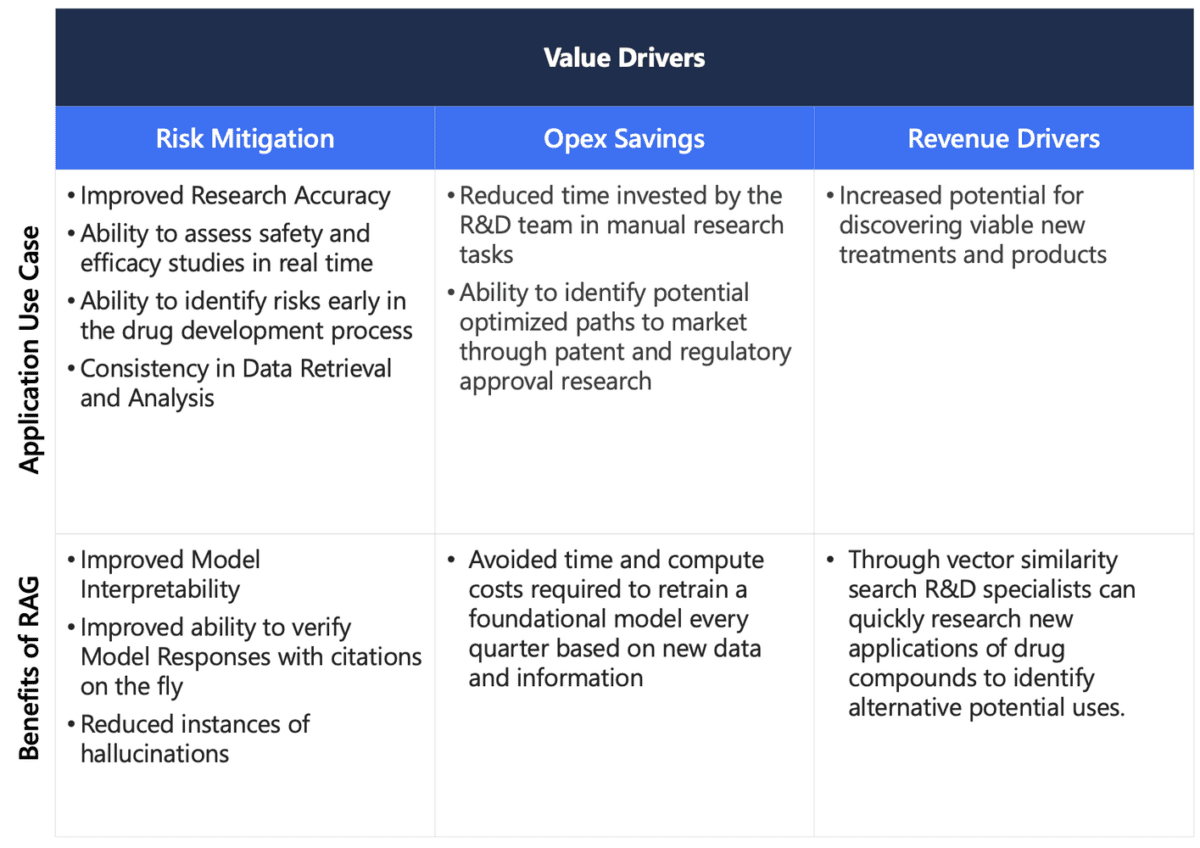
Figure 2. Value Framework for Application & Technical Approach
As explored, RAG can address material concerns surrounding Generative AI, which include generating reliable, verifiable responses and capitalizing on the organization’s unique knowledge. It’s a strong example of how designing the right architecture, AI stack, and strategy upfront can completely transform the outcome of a project. As Philip Moyer aptly noted in a recent edition of The Prompt, “Successful adoption is the combination of targeting the right use cases and investing in the appropriate platform capabilities.” Key elements such as embeddings models and Vector Databases exemplify components of these essential platform capabilities that can bring interpretability and long-term memory to Generative Chat applications. Hence, RAG not only stands as a promising method to develop trust in AI, but also to harness and utilize an organization’s intellectual capital and data assets in a powerful and practical way.

Rab Bruce-Lockhart
Chief Revenue Officer
15:28 – 21st January 2025
Ready to discover more?
Contact us and we’ll set up a video call to discuss your requirements in detail.